0718 学习了新版viewmodel存储数据
viewmodel的重建过程:
和前面相结合,一切都说得通了。我们再来捋一捋viewModel存储、恢复数据的过程。
- 第一次创建ViewModel时,ViewModelStore利用HashMap将新创建的ViewModel对象存储了起来;
- 在手机横竖屏时,Activity被销毁之前,会触发onRetainNonConfigurationInstance,对ViewModelStore进行存储;
- Activity重建后,Activity会重新走onCreate生命周期,并且会再次去获取ViewModel对象。而这次ViewModel的获取与第一次创建不同,它会通过ViewModelStoreOwner先获取该Activity重建之前所保存的ViewModelStore,接着在ViewModelStore中根据Key,找到重建之前的ViewModel,进而恢复数据。
上述是大致流程,但是更详细的系统在哪里去存起来对应的 Activity.NonConfigurationInstances lastNonConfigurationInstances 实际上还没有找到,这里保存着viewmodel store的父数据结构,在这里叫activity,那么具体存起来的时候在哪里呢?看代码:
/* 这个数据结构就是在ActivityThread里面定义的,而ActivityClientRecord里面保存了NonConfigurationInstances
*/
final ArrayMap<IBinder, ActivityClientRecord> mActivities = new ArrayMap<>();
/* 是哪里赋值的呢,在第一次创建Activity的时候就会放进去,如果此时但是此时我们的主角别置为空了,那么什么时候给置为非空呢,是在performDestroyActivity中,销毁之前让你保存状态,
*/
private Activity performLaunchActivity(ActivityClientRecord r, Intent customIntent) {
synchronized (mResourcesManager) {
mActivities.put(r.token, r); // 这里仅仅初始化r,占坑
}
}
ActivityClientRecord performDestroyActivity(IBinder token, boolean finishing, int configChanges, boolean getNonConfigInstance, String reason) {
if (getNonConfigInstance) {
try {
r.lastNonConfigurationInstances
= r.activity.retainNonConfigurationInstances();// 这个咱们ComponentActivity重写的,提供对应的缓存
} catch (Exception e) {
}
}
}
到这里,viewmodel是怎么缓存的已经解开其神秘的面纱了,已经不是retainFragmet那一套,而仅仅是一些数据结构去保存,这名字也挺好,NonConfigurationInstances,不随着配置改变的东西,对于viewmodel来说,无论怎么转屏因为只是一份共有的数据 ,所以这里保存好之后,新的还是会接到咱们viewmodel里面的数据的,少了加载过程,省流量体验好。
最终这里虽然Activity销毁重建了,但是ActivityThread已经在onCreate前通过attach给到Activity这些东西了,我们想想为什么设计的在attach之后置空呢,这个是因为既然新的已经拿到viewmodel了,那么我们就要把缓存的干掉,因为不能保证新的不会改变viewmodel或者类似NoConfig里面的内容,这样能够始终保存last的状态,也是人家名字的含义,真棒。
0720 注解之元注解
在使用注解处理器的时候,本来是为了处理有的类是我们针对的注解,那么就根据生成的代码去自动插进去,发现自定义的apt注解asm扫描不到,根据编译打印日志发现apt是在asm之前的,那么问题在哪里呢,主要问题是发生在注解定义的时候元注解声明的标志有问题,声明了SOURCE而不是RUNTIME,这个源码阶段可见,运行时不可见,那么对于ASM来说也是不可见的了,可以看下BINARY是否可见,理论上是可见的,编译到二进制了。正确,声明注解生命周期的元注解如果asm需要的话至少要 BINARY 因为ASM就是扫描的class呀,嘿嘿嘿。
// 定义的注解,编译时作用在类上
@Target(AnnotationTarget.CLASS)
@Retention(AnnotationRetention.BINARY) // 如果asm要处理,这里至少可见
annotation class GrowthClass
0721 学习了插桩
学习hilt那种形式,只要知道了如何插入对应的东西,那么就能随心所欲的去做自己的工作了,核心代码如下,首先判断当前类是否是要注入的那个,因为我的类声明是对应的某个注解,例如我这边是
// 这里会遍历访问类的注解,值得注意的是需要至少BINARY ASM才能扫描到
override fun visitAnnotation(descriptor: String?, visible: Boolean): AnnotationVisitor {
println("XUEXI visitAnnotation +++++++++++ visitAnnotation $descriptor class is ----->>>>>> $className")
updateIsTarget(descriptor)
return super.visitAnnotation(descriptor, visible)
}
// 这里判断是否是有目标注解的类,这里需要注意他这里的全限定名,以及分号等等
private fun updateIsTarget(descriptor: String?) {
isTargetClass = "Lcom/xpj/growthannotation/GrowthClass;".equals(descriptor)
}
MethodVisitor里面:
override fun visitMethodInsn(
opcodeAndSource: Int,
owner: String?,
name: String?,
descriptor: String?,
isInterface: Boolean
) {
super.visitMethodInsn(opcodeAndSource, owner, name, descriptor, isInterface)
// 这里会遍历所有的方法访问,因为我们知道插入点是 setContentView 之后,所以这里直接判断
if (isTarget && "setContentView".equals(name)) {
// 这里开始是通过ASM tool查看的本身调用应该怎么写
val label2 = Label()
mv.visitLabel(label2)
// mv.visitLineNumber(38, label2)
mv.visitFieldInsn(
GETSTATIC,
"$owner" + "_growthBindView",
"Companion",
"L" + "$owner" + "_growthBindView" + "\$Companion;"
)
mv.visitVarInsn(ALOAD, 0)
mv.visitMethodInsn(
INVOKEVIRTUAL,
"$owner" + "_growthBindView" + "\$Companion",
"growthBindView",
"(L$owner;)V",
false
)
// 这里结束,只是少了一个visitLineNumber然后别的泛化了一下就可以了
}
}
总结:
- 这里需要和apt协同,首先要保证apt在asm之前处理的,不然我们这里会找不到对应的类
- 然后具体工作中根据我们自定义的注解作为入口与判断点,去做相应的插入点寻找
- 核心用法,或者说是以后写ASM的核心点,主要就是需要对ASM TOOL的灵活使用,如果你想插入的语句不知道要怎么写,那么我们就在代码里面写一下然后反编译去看看怎么写,然后写到我们自己插件里,然后泛化就行了
- 元注解的使用,主要是需要自己的目的,知道在什么情境下用什么作用域的注解,例如SOURCE 还是 BINARY 还是 RUNTIME
- 善用工具,特别是调试工具, 核心用法是 5.1 创建remote config 5.2 执行 ./gradlew clean; ./gradlew assembleDebug -Dorg.gradle.debug=true --no-daemon 首先clean是为了清除生成的文件等,不然如果是增量可能调用不到我们的断点处 5.3 在as内点击debug小图标,有绿色小点证明开始debug,到目标模块后会执行断点了,这时候我们可以看任何信息
0724 总结输出
亏我用了这么久的Xmind没想到回车就是插入同级主题,难怪一直找不到快捷键,我还疑惑,这么个高频操作竟然没有快捷键吗。。而插入副主题是command + 回车,上下左右键移动主题选择。
0801 解决了瀑布流错排问题
解决了recyclerview瀑布流错排的问题,这个问题主要是每次瀑布流重新计算高度,然后每个holder位置复用的时候,会产生空隙,这时候holder的高度填不满就会引发recyclerview的重排序,这时候就会有左右位置互换的问题,现在的解决方案是什么呢。
- 在对应的瀑布流data里加上高度每次onBindViewholder的时候重新设置回对应里面holder的view里面
- 这个高度的获取怎么弄呢,就是根据里面的不同元素按照设计图上给的高度去计算,包括之间的margin也要加上
- 这里的高度计算我曾使用view.post去获取,这时候的时机是晚的,下一步的优化点应该是使用一个自定义布局,例如基于约束的或者基于frame layout的布局,然后去让他自己去解析对应的布局再计算高度,
- 还遇到一个问题是,即使使用了固定高度还是会有重排序,问题的根源是我在使用recyclerview的时候增加和结束动画的时候用的 notifyDataChange 去通知的数据有改变,这时候就会导致数据会多刷新,解决方式是使用 notifyDataInsert(增加动画时)和 notifyDataRemoved(移除动画时),这时候就不会有频繁的刷新回调了,保持了高度数据也保证了瀑布流不重排。
- 上述问题也说明了自己使用不当导致的问题,这个还需要去研究和学习recyclerview的,这个还有一个来自recyclerview的 diffutil 还是值得学习和研究的。有了listview为啥还要有recyclerview呢,这个就是需要着重看到recyclerview的核心本质和优势在哪里。
0803 工作中学习记录
- 使用recyclerview的addItemDecroration的时候需要判断是否已经存在了,因为它支持多个如果不判断会发生同一个itemDecoration被重复添加体现到UI上就是间距越来越大。
- 使用merge标签的时候必须要把这个view attachRoot设置为true,因为它本身不依赖任何已经有的布局,另外使用merge内外布局必须一样,否则也会有问题,而recyclerview等一系列要求不能attachRoot为true所以使用merge的布局不能使用在对应的recyclerview中。
- attachRoot 是否为 true的意思是是否立刻添加子view到父viewgroup中,因为recyclerview存在复用以及动态添加移除view所以这个要自己去管理,addView和removeView。
- 又体现了架构的好处,我的首页因为有processor和transfer这些角色,因此适配另一个接口回很快,直接创建新的processor即可,并且,我的使用也是依赖注入的思想,processor是外部传入的,具体调用者无感知就完成了替换。
0806 学习使用Charles断点
使用Charles断点修改返回值功能,在对应的接口上右击选择break points然后再次请求这个接口的时候就能对request和response进行修改了,可以修改里面的内容达到调试目的,例如让某些数据异常缺失了,或者多于了啥的,看看端上的容错是否ok。
0814 反编译步骤
// 1. copy 文件到目标文件夹
cp ~/code/github/MyGrowPath/app/build/outputs/apk/debug/app-debug.apk .
// 2. 执行非smali方式的反编译
./apktool d -s app-debug.apk
// 3. copy 生成的文件到dex2jar
mv app-debug dex2jar
// 4. dex解析为对应的jar包,这里可能多个classes.dex文件,找到自己感兴趣的
sh dex2jar/dex2jar-2.0/d2j-dex2jar.sh dex2jar/app-debug/classes.dex
// 5. jd-gui查看生成的jar
使用扩展函数添加 dialog
// 如果是继承于 FragmentActivity 可以这样写,如果是 Activity 则需要用 dialog。
fun FragmentActivity.showDia() = run {
val dia = KSCoroutinesFrag()
// 注意这里的 android.R 因为资源是 android 的,这样才能正常使用
supportFragmentManager.beginTransaction().add(android.R.id.content, dia)
.commitAllowingStateLoss()
}
优化在 IO 中解析
解析绘本首页数据时候,用协程在 IO 线程中解析,发现使用 flow 方式可以,使用协程直接解析和使用 async 都会有异常,目前没有研究具体原因是啥, flow 可以就可以吹逼一下子了。
// todo 可以验证这里消耗了多少时间,这样改造之后,就不会在主线程阻塞解析数据了,唉,不得不感叹我原来的
// 框架可太好用了,这里随随便便添加协程和流相关滴,这里可以用协程 async 做,因为只有一个值
val flowR = flow<HPDataV4?> {
val start = System.currentTimeMillis()
val re = processor?.process(data)
Log.e("PANJIE", "use time ${Thread.currentThread().name} ${System.currentTimeMillis() - start}")
emit(re)
}.flowOn(Dispatchers.IO)
// todo async 方式
// val jjj = CoroutineScope(Dispatchers.IO).async {
// processor?.process(data)
// }
// todo runBlocking with 协程作用域方式
// val jj1 = runBlocking(Dispatchers.IO) {
// processor?.process(data)
// }
CoroutineScope(Dispatchers.Main).launch {
// if (jj1 != null) {
// v4HPData?.value = HPV4Result(rType, null, jj1)
// } else {
// v4HPData?.value = HPV4Result(rType,
// NetworkErrorBean(V_DEFAULT_ERROR_CODE, ERROR_PROCESS), null)
// }
// 两种方式,一种 async 协程并发,我这里
// val resultq = jjj.await()
// if (resultq != null) {
// v4HPData?.value = HPV4Result(rType, null, resultq)
// } else {
// v4HPData?.value = HPV4Result(rType,
// NetworkErrorBean(V_DEFAULT_ERROR_CODE, ERROR_PROCESS), null)
// }
flowR.collect { result ->
if (result != null) {
v4HPData?.value = HPV4Result(rType, null, result)
} else {
v4HPData?.value = HPV4Result(rType,
NetworkErrorBean(V_DEFAULT_ERROR_CODE, ERROR_PROCESS), null)
}
}
}
go 同一包名调用
原因:执行file2.go时未一起编译file1.go,所以报错
解决:先一起编译,再执行,如:
先go build .
再go run file1.go file2.go
或者直接go run *.go
goland中自定义的包无法引入,提示 package ** is not in GOROOT (*)
解决步骤:
第一步,在项目的当前目录里,执行命令:go mod init ,会在当前项目目录下自动创建go.mod文件。
第二步,在命令行下,进入当前项目目录,执行命令:go run main.exe,此时会自动下载和关联该项目用到的包。 这一步貌似也不是必须的,有了 go.mod 接下来在运行的时候再配置哪里运行单文件改为 package 就可以了
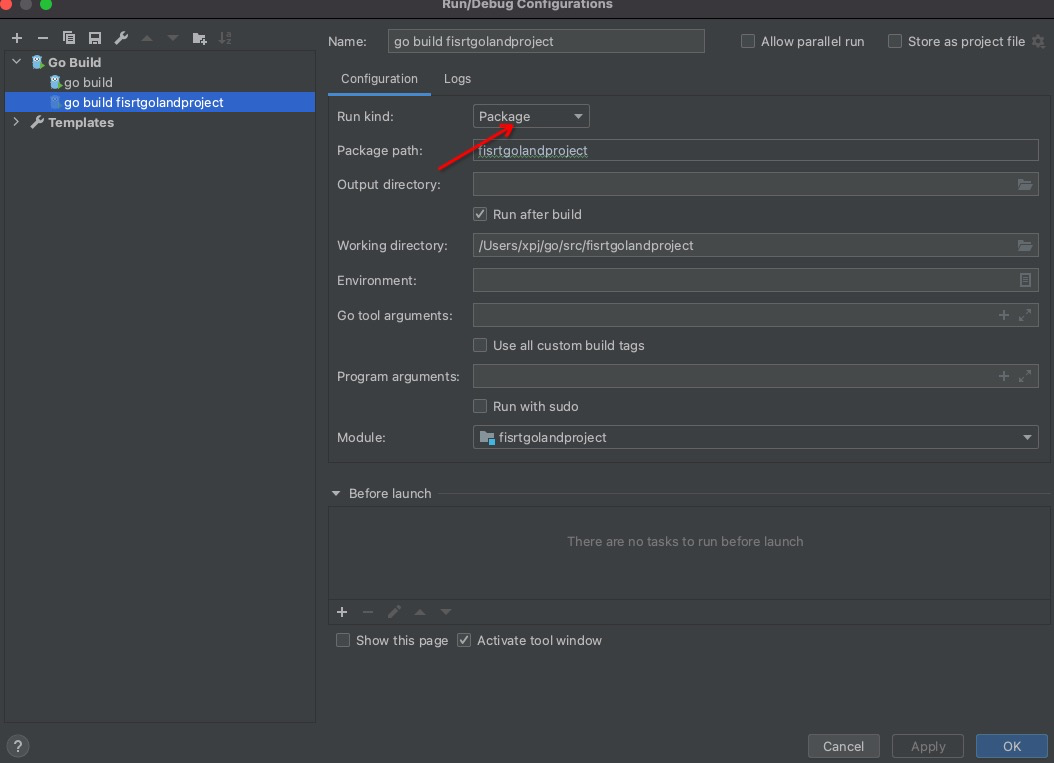
执行完后,go.mod文件内容中会有引用的相关包。项目就可以正常运行了。
ubuntu 20.04 上使用 openvpn
步骤:
# 1. 将对应的 ovpn 文件放到 /etc/openvpn/ 下
# 2. 使用 sudo 启动 vpn
sudo openvpn /etc/openvpn/ipalfish.ovpn
# 3. 登录密码和用户名为 lpad 账号密码
xpj12539 / Xpj1d6
链表反转
链表翻转,使用 linkedlist 当 stack 栈用,然后使用 getLast 啥的从最后取,倒序取就是 stack 了,去了之后构建一个新的链表,就翻转了。 也可以直接用栈,只是 Java 的栈实现没有 top 而已,pop 就相当于把顶端的给推出去。